Hadoop是的一个分布式系统基础架构,可以为海量数据提供存储和计算。它的基础架构十分简单,主要分为三部分:
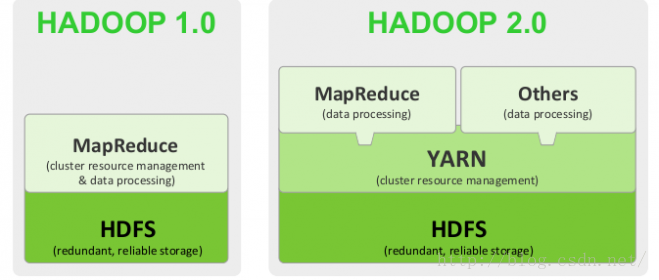
HDFS, 为海量数据提供存储
MapReduce用于分布式计算
YARN进行资源管理
相比与Hadoop1,2.0在很多方面进行了改进,其中最大的改进要属于YARN,它实现了资源的调度和管理,取代了JobTracker,使得基于HDFS之上可以运行很多不同的计算框架,如Spark。同时该实现了NameNode的HA方案,提供两个NameNode,当一个宕机后另一个可以及时补充。HDFS federation方案减小NameNode的压力,采用多个NameNode共同管理datanode的策略。将RPC独立成一个可插拔的模块。
下面就对这三个模块进行简要的介绍。
HDFS
分布式文件系统,部署在多台廉价的硬件设备上,并提供了海量数据存储和高吞吐量和高容错性的特点。它比较适合一次写入,多次读取,适合存储大文件,不适合小文件,并且不适合需要低延迟率的场景。HDFS的架构中有四种角色,一种是NameNode,另一种是DataNode,其他两个是Client和SecondNameNode。NameNode主要负责元数据的管理,维护名字空间,DataNode主要负责存储文件块。NameNode来管理datanode与文件块的映射关系。
使用HDFS,和读写两个操作非常相关。
读操作
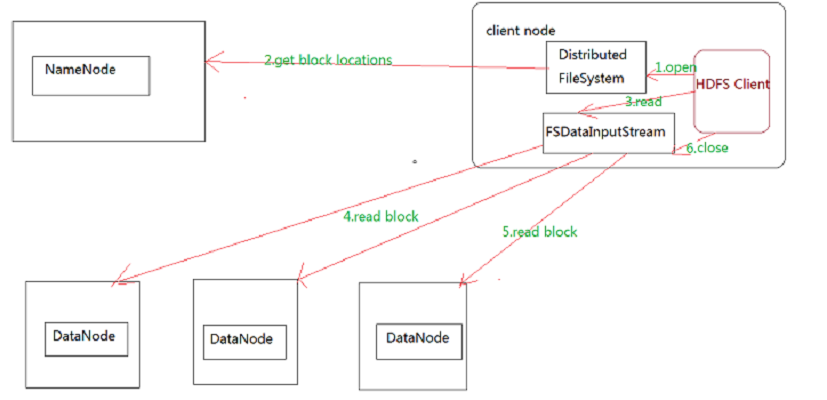
首先调用FileSystem对象的open方法,其实获取的是一个
DistributedFileSystem的实例。DistributedFileSystem通过RPC(远程过程调用)获得文件的第一批block的locations,同一block按照重复数会返回多个locations,这些locations按照hadoop拓扑结构排序,距离客户端近的排在前面。如:12block1:host2,host1,host3block2:host7,host8,host4
那么读取block1时会优先去读host2,度block2时会优先读取host7
前两步会返回一个
FSDataInputStream对象,该对象会被封装成DFSInputStream对象,DFSInputStream可以方便的管理datanode和namenode数据流。客户端调用read方法,DFSInputStream就会找出离客户端最近的datanode并连接datanode。数据从datanode源源不断的流向客户端。
如果第一个block块的数据读完了,就会关闭指向第一个block块的datanode连接,接着读取下一个block块。这些操作对客户端来说是透明的,从客户端的角度来看只是读一个持续不断的流。
如果第一批block都读完了,
DFSInputStream就会去namenode拿下一批blocks的location,然后继续读,如果所有的block块都读完,这时就会关闭掉所有的流。
写操作
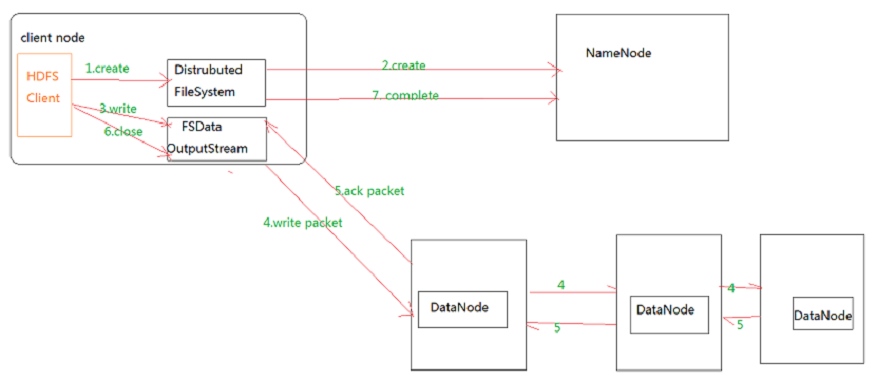
与普通文件系统不同的是,在 HDFS中,如果一个文件小于一个数据块的大小,并不占用整个数据块存储空间。
客户端通过调用 DistributedFileSystem 的create方法,创建一个新的文件。
DistributedFileSystem通过RPC(远程过程调用)调用NameNode,去创建一个没有blocks关联的新文件。创建前,NameNode会做各种校验,比如文件是否存在,客户端有无权限去创建等。如果校验通过,NameNode就会记录下新文件,否则就会抛出IO异常。
前两步结束后会返回FSDataOutputStream的对象,和读文件的时候相似,FSDataOutputStream被封装成DFSOutputStream,DFSOutputStream可以协调NameNode和DataNode。客户端开始写数据到DFSOutputStream,DFSOutputStream会把数据切成一个个小packet,然后排成队列 data queue。
DataStreamer会去处理接受dataqueue,它先问询NameNode这个新的block最适合存储的在哪几个DataNode里,比如重复数是3,那么就找到3个最适合的 DataNode,把它们排成一个 pipeline。DataStreamer 把 packet按队列输出到管道的第一个 DataNode 中,第一个 DataNode又把 packet 输出到第二个 DataNode 中,以此类推。
DFSOutputStream还有一个队列叫ack queue,也是由packet组成,等待DataNode的收到响应,当pipeline中的所有DataNode都表示已经收到的时候,这时akc queue才会把对应的packet包移除掉。
客户端完成写数据后,调用close方法关闭写入流。
DataStreamer 把剩余的包都刷到 pipeline 里,然后等待 ack 信息,收到最后一个 ack 后,通知 DataNode 把文件标示为已完成。
YARN
YARN将JobTracker拆分成了两个独立的服务:一个全局的资源管理器ResourceManager和每个应用程序特有的ApplicationMaster。ResourceManager负责整个系统的资源管理和分配,而ApplicationMaster负责单个应用程序的管理.
YARN总体上仍然是Master/Slave结构。在整个资源管理框架中,ResourceManager为Master,NodeManager为Slave
ResourceManager
它是一个全局的资源管理器,负责整个系统的资源管理和分配,主要由调度器和应用程序管理器两个组件构成。
调度器:根据容量、队列等限制条件,将系统中的资源分配给各个正在运行的应用程序。调度器仅根据应用程序的资源需求进行资源分配,而资源分配单位用一个抽象概念“资源容器”(简称Container)表示,Container是一个动态资源分配单位,它将内存、CPU、磁盘、网络等资源封装在一起,从而限定每个任务使用的资源量。
应用程序管理器:负责管理整个系统中所有的应用程序,包括应用程序提交、与调度器协商资源以启动ApplicationMaster、监控ApplicationMaster运行状态并在失败时重新启动它等。
NodeManager
它是每个节点上的资源和任务管理器,它不仅定时向ResourceManager汇报本节点上的资源使用情况和各个Container的运行状态,还接收并处理来自ApplicationMaster的Container启动/停止等各种请求。
ApplicationMaster
用户提交的每个应用程序均包含1个ApplicationMaster,主要功能包括与ResourceManager调度器协商以获取资源、将得到的任务进一步分配给内部的任务、与NodeManager通信以启动/停止任务、监控所有任务运行状态并在任务运行失败时重新为任务申请资源以重启任务等。
工作流程
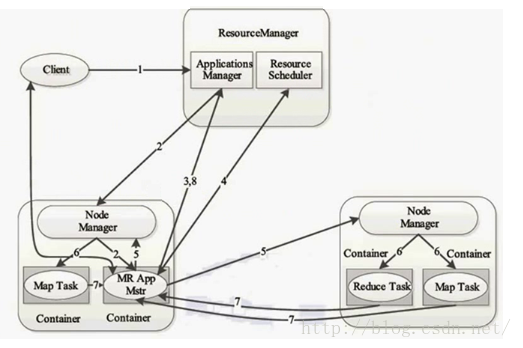
用户向YARN中提交应用程序,其中包括用户程序、
ApplicationMaster程序、ApplicationMaster启动命令等。ResourceManager为应用程序分配第一个Container,并与对应的NodeManager通信,要求它在这个Container中启动应用程序的ApplicationMaster。ApplicationMaster首先向ResourceManager注册,这样用户可以直接通过ResourceManager查看应用程序的运行状态,然后ApplicationMaster为各个任务申请资源,并监控它们的运行状态,直到运行结束,即重复步骤4-7。ApplicationMaster采用轮询的方式通过RPC协议向ResourceManager申请和领取资源。一旦
ApplicationMaster成功申请到资源,便开始与对应的NodeManager通信,要求它启动任务。NodeManager为任务设置好运行环境(包括环境变量、JAR包、二进制程序等)后,将任务启动命令写到一个脚本中,并通过运行该脚本启动任务。各个任务通过某个RPC协议向
ApplicationMaster汇报自己的状态和进度,使ApplicationMaster能够随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务。在应用程序运行过程中,用户可随时通过RPC向ApplicationMaster查询应用程序的当前运行状态
可见,ApplicationMaster作为一个应用程序的管理这,也被看成是一个任务,需要申请资源,在某台机器上的Container中运行,在运行期间向调度器去申请资源给其他的任务执行。
MapReduce
待续