之前我们提过Kafka的基本框架,知道Producer采用Push的方式发送消息给集群,Consumer采用Pull的方式从集群中拉取消息。那么,对于写入一条消息,它的基本流程是怎样的呢?下面,我们讲沿着:Producer发布消息 -> 消息存储格式 -> Consumer消费消息这三个步骤展开。
Topic创建
在讲解消息的发布和订阅之前,集群首先要有topic才行,因此本小节先讲讲topic的创建。
Controller控制器
Kafka里的服务器都叫做Broker,但是却有一个机器叫做Controller。Kafka集群中的其中一个Broker会被选举为Controller,主要负责Partition管理和副本状态管理,也会执行类似于重分配Partition之类的管理任务。
而创建Partition,就需要Controller的协调。
创建topic的过程,客户端的操作很简单,它甚至不需要有Kafka集群的存在,因为kafka集群只负责存数据,至于它存的是哪个topic的数据,估计它自己都不知道,这些对应信息都存储在Zookeeper中。因此客户端创建一个topic时,只需要和zookeeper通信,在对应的znode节点新建一个子节点即可。但是有了topiic,还需要分配topic的partition,还要选出partition的leader,以及ISR等,而这些工作,都是由controller来完成。
- controller 在 ZooKeeper 的 /brokers/topics 节点上注册 watcher,当 topic 被创建,则 controller 会通过 watch 得到该 topic 的 partition/replica 分配。
- controller从 /brokers/ids 读取当前所有可用的 broker 列表,对于 set_p 中的每一个 partition:
2.1 从分配给该 partition 的所有 replica(称为AR)中任选一个可用的 broker 作为新的 leader,并将AR设置为新的 ISR
2.2 将新的 leader 和 ISR 写入 /brokers/topics/[topic]/partitions/[partition]/state- controller 通过 RPC 向相关的 broker 发送 LeaderAndISRRequest。
从上术的流程可以看出,它利用了zookeeper的watcher机制,动态监听topic节点的改变,从而进行分配partition,选择leader,设置ISR并反写到zookeeper中。
Producer发布消息
我们来回顾一下,要发送一条消息,首先一定要指定一个topic,表明他是那一种类的消息,然后一条消息要发送到一个broker上的某一个partition中,由于需要支持HA,所以对这条消息进行持久化的时候,肯定要同时写入多个partition中,成功之后在回ack给client。
每条消息都被 append 到 patition 中,属于顺序写磁盘(顺序写磁盘效率比随机写内存要高,保障 kafka 吞吐率)。
整体的流程图如下:

写入消息分为下面几个步骤:
确定partition
这是第一步,由于一个topic对应这多个partitions,首先要确定和哪个partition进行通信并存储,发送到broker时,分区算法选择将其存储到哪一个 partition. 他遵循以下规则:
- 指定了 patition,则直接使用;
- 未指定 patition 但指定 key,通过对 key 的 value 进行hash 选出一个 patition
- patition 和 key 都未指定,使用轮询选出一个 patition。
找到partition的通信地址
由于系统实现了HA,因此,一个partition有多个replica,Producer 先从 Zookeeper 的 “/brokers/…/state” 节点找到该 partition 的 leader, 之后就只与该leader通信。注意,这里的leader是指partition的leader,而事实上,kafka集群不像zookeeper一样,有leader管理,发起提议等,它是没有leader的。
数据传输
- producer 将消息发送给该 leader
- leader 将消息写入本地 log
- followers 从 leader pull 消息,写入本地 log 后 leader 发送 ACK
- leader 收到所有 ISR 中的 replica 的 ACK 后,增加 HW(high watermark,最后 commit 的 offset) 并向 producer 发送 ACK
这里我们一定想到了各种意外的情况,比如说网络中断,某个partition宕机了等,因此,保证消息的传输有几种方式:
- At most once 消息可能会丢,但绝不会重复传输
- At least one 消息绝不会丢,但可能会重复传输
- Exactly once 每条消息肯定会被传输一次且仅传输一次
消息存储格式
一个topic有一个partition?和broker数一样? 这配置文件里会进行设置: server.properties 中的 num.partitions=3
一条消息的格式如下:
一个topic的一个partition,物理上对应着一个文件夹,里面存储这所有该partition的消息。没条消息都可以对应一个64位的offest,offset标注了这条消息在发送到这个分区的消息流中的起始位置,每个日志文件的名称都是这个文件第一条日志的offset.所以第一个日志文件的名字就是00000000000.kafka.所以每相邻的两个文件名字的差就是一个数字S,S差不多就是配置文件中指定的日志文件的最大容量。
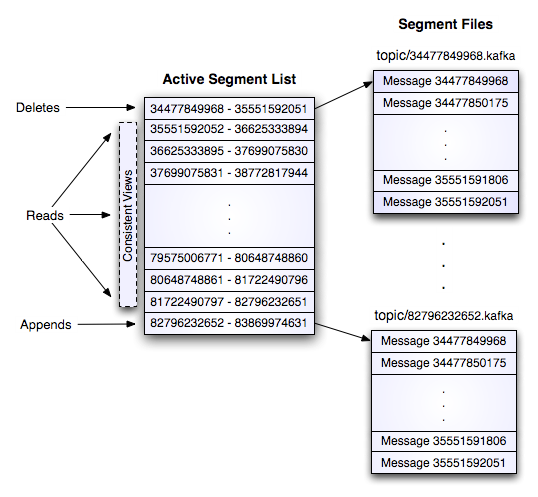
文件夹下有一个索引文件,和若干个.kafka文件。
Consumer订阅消息
消费者要比生产者复杂得多。由于kafka不会为消费者维护offset,因此,要么自己(Consumer)维护offset,低级API,要么交给Zookeeper维护, 高级API。此外还有Consumer Group的概念,一个Consumer Group有多个Consumer,一条消息只会被其中的一个Consumer消费。一般的,Consumer的数量不要大于Partition的数量,这是因为一个Partition只能被一个Consumer消费,Consumer多了就会有的轮空。
Low Level API
这种API维持了单一个broker的连接,它是没有状态的,因此每次去消费数据,都有带上offset,因此它可以通过重新设置offset多次消费同一份数据。这种操作方式更灵活,但是也更繁琐。一般的,即使使用Low Level API,也会把offset手动同步到zookeeper上,当我们处理失败了,就不去更新offset。
此外,选择Partition的Leader,处理Leader的故障转移等也需要客户端去实现。
High Level API
更自动化的一种操作。consumer的offset会自动同步到zookeeper上,也会自动的去选取leader,leader失效时重试等。但是它也有缺点,就是它保证了每次都取的都是下一条消息,不能够回搠去读,因此,无论处理这条消息是否成功,都不能重复读了,这显然有些不合理。
Consumer与Partition的关系
如果consumer比partition多,是浪费,因为kafka的设计是在一个partition上是不允许并发的,所以consumer数不要大于partition数
如果consumer比partition少,一个consumer会对应于多个partitions,这里主要合理分配consumer数和partition数,否则会导致partition里面的数据被取的不均匀
如果consumer从多个partition读到数据,不保证数据间的顺序性,kafka只保证在一个partition上数据是有序的,但多个partition,根据你读的顺序会有不同
增减consumer,broker,partition会导致rebalance,所以rebalance后consumer对应的partition会发生变化